Introduction to E-commerce Fraud

Understanding E-commerce Fraud
E-commerce fraud encompasses a wide range of deceptive activities targeting online businesses and consumers. It's a significant concern in the modern digital marketplace, impacting both individual shoppers and large corporations. These fraudulent activities can range from simple scams to sophisticated schemes, often designed to exploit vulnerabilities in online systems and payment processes. Understanding the various types of fraud is crucial for both businesses and consumers to protect themselves and mitigate potential losses.
From phishing attacks that aim to steal personal information to counterfeit products flooding the market, the landscape of e-commerce fraud is constantly evolving. This evolution necessitates continuous vigilance and adaptation in security measures. Protecting sensitive data and ensuring secure transactions are paramount in combating this pervasive issue.
Common Types of E-commerce Fraud
Several common types of e-commerce fraud exist, each with unique characteristics and methods. One prevalent type is phishing, where fraudsters attempt to trick individuals into revealing personal information like passwords and credit card details. Another significant category is the selling of counterfeit goods, which can severely impact consumer trust and damage the reputation of legitimate businesses. These fraudulent activities can cause significant financial and reputational harm.
Payment fraud, involving unauthorized transactions or the use of stolen payment information, is another major concern for online businesses. This type of fraud often requires complex security measures and meticulous transaction monitoring to detect and prevent.
Finally, identity theft, where fraudsters impersonate individuals to make purchases or gain access to accounts, is a serious threat to both businesses and consumers. This necessitates strong authentication protocols and robust identity verification systems.
Preventing and Mitigating E-commerce Fraud
Businesses and consumers can take proactive steps to prevent and mitigate e-commerce fraud. Implement robust security measures, including strong passwords, multi-factor authentication, and regular security audits, to protect sensitive data from unauthorized access. Education plays a crucial role in fraud prevention, with awareness campaigns empowering consumers to recognize and avoid fraudulent activities. By being vigilant and informed, individuals can significantly reduce their risk of becoming victims of e-commerce fraud.
For businesses, implementing secure payment gateways, employing fraud detection systems, and regularly updating security protocols are essential. Partnerships between businesses and law enforcement can also play a critical role in combating e-commerce fraud, facilitating the identification and prosecution of perpetrators. A multi-faceted approach involving both individuals and businesses is key to combating the evolving landscape of online fraud.
The Role of Machine Learning in Fraud Detection
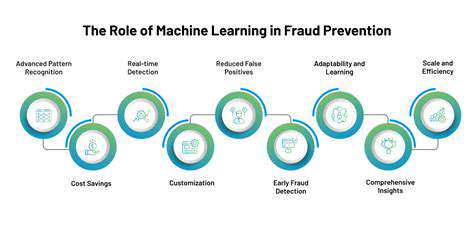
Machine Learning's Impact on Fraud Detection
Machine learning (ML) algorithms are revolutionizing fraud detection by enabling systems to identify patterns and anomalies in vast datasets that would be impossible for humans to discern. These algorithms are trained on historical transaction data, learning to recognize fraudulent activities, and adapting to evolving fraud schemes in real-time. This proactive approach allows for a significant reduction in fraudulent transactions compared to traditional rule-based systems.
By analyzing intricate financial transactions, ML models can identify subtle indicators of fraudulent behavior. This capability is particularly useful in detecting sophisticated fraud schemes that might otherwise go unnoticed. This proactive approach to fraud detection is crucial for businesses to safeguard their financial assets and maintain customer trust.
Data Preparation for Effective ML Models
The quality and quantity of data are paramount for successful machine learning models in fraud detection. A critical aspect of this process involves data cleaning, handling missing values, and transforming data into a format suitable for the chosen ML algorithms. Preparing data accurately ensures that the model learns from reliable information, leading to more precise fraud detection outcomes.
Feature engineering is another essential step. This involves creating new features from existing data to enhance the model's ability to identify subtle patterns. This process can involve aggregating data points, deriving ratios, and transforming variables. Careful data preparation is the foundation for building robust and accurate fraud detection models.
Types of Machine Learning Algorithms Used
Various machine learning algorithms are employed in fraud detection, each with its strengths and weaknesses. Supervised learning algorithms, like logistic regression and support vector machines, are commonly used to classify transactions as fraudulent or legitimate based on predefined features. Unsupervised learning algorithms, such as clustering and anomaly detection, are valuable for identifying unusual patterns that deviate significantly from the norm. These algorithms often work in tandem to provide a comprehensive fraud detection solution.
The choice of algorithm depends on the specific characteristics of the data and the desired level of accuracy. Selecting the right algorithm is critical for achieving optimal results in fraud detection.
Real-World Applications and Examples
Machine learning is already being implemented by numerous financial institutions to detect various forms of fraud, from credit card fraud to identity theft. These systems are constantly evolving, adapting to new trends and fraudulent tactics. By analyzing transaction patterns, location data, and other factors, ML algorithms can identify suspicious activities in real-time, enabling swift intervention and minimizing financial losses.
For example, an online retailer might use ML to detect fraudulent returns or unauthorized account access. This proactive approach to fraud detection is vital in maintaining the security of online transactions. This is a prime example of how ML is transforming the way financial institutions and businesses approach fraud prevention.
Challenges and Future Directions
Despite the significant progress, there are challenges in implementing machine learning for fraud detection. These include the need for large, high-quality datasets, the potential for bias in the models, and the ongoing evolution of fraudsters' tactics. Overcoming these challenges is essential for maintaining the effectiveness of these systems.
Future research and development will likely focus on addressing these challenges and enhancing the accuracy and efficiency of fraud detection systems. The development of more robust and adaptive algorithms is crucial for maintaining a competitive advantage in the fight against fraud. This includes exploring new techniques like deep learning and reinforcement learning to further improve fraud detection capabilities.
Key Machine Learning Techniques for Fraud Detection

Supervised Learning
Supervised learning algorithms learn from labeled data, where each data point is associated with a corresponding target value. This target value acts as a guide, allowing the algorithm to learn the relationship between the input features and the desired output. Examples include tasks like image recognition, where the algorithm is trained on images labeled with the objects they contain, and spam detection, where emails are labeled as either spam or not spam. Supervised learning models can then predict the target variable for new, unseen data.
Common supervised learning techniques encompass regression, which predicts continuous values, and classification, which predicts categorical values. Regression models aim to establish a relationship between variables to forecast continuous outcomes, such as predicting house prices or stock market trends. Classification models, on the other hand, categorize data points into predefined groups, for instance, determining if an email is spam or identifying a customer segment.
Unsupervised Learning
Unsupervised learning algorithms work with unlabeled data, where the target variable is unknown. The goal is to discover hidden patterns, structures, or relationships within the data. This can involve clustering similar data points together or dimensionality reduction, where the algorithm finds ways to represent the data with fewer variables while preserving important information.
Clustering techniques, such as k-means clustering, group similar data points into clusters, often used in customer segmentation or anomaly detection. Dimensionality reduction methods, such as Principal Component Analysis (PCA), find a smaller set of variables that capture the most variance in the data, simplifying complex datasets and potentially improving model performance.
Reinforcement Learning
Reinforcement learning (RL) differs from supervised and unsupervised learning in that it involves an agent interacting with an environment. The agent learns through trial and error, receiving rewards or penalties based on its actions. This process allows the agent to learn optimal strategies to maximize cumulative rewards over time.
RL is particularly useful in robotics, game playing, and autonomous systems, where an agent must learn to navigate complex environments and make decisions to achieve a specific goal. Examples include training robots to perform tasks or developing algorithms to play games like Go or chess.
Deep Learning
Deep learning algorithms utilize artificial neural networks with multiple layers (hence deep) to extract complex patterns and features from data. These networks excel at processing large amounts of data, making them suitable for image recognition, natural language processing, and speech recognition.
Deep learning models are particularly powerful in tasks involving complex relationships and high-dimensional data. They learn hierarchical representations, where lower layers learn basic features and higher layers combine them to extract more abstract concepts. This allows deep learning models to achieve state-of-the-art performance in many applications.
Natural Language Processing (NLP)
Natural language processing (NLP) focuses on enabling computers to understand, interpret, and generate human language. NLP techniques are crucial for tasks such as sentiment analysis, machine translation, and text summarization.
NLP techniques allow computers to process and understand human language, opening up possibilities for applications like chatbots, virtual assistants, and automated document analysis. These technologies can process large volumes of text data, extract insights, and automate many tasks involving human language.
Model Evaluation and Selection
Evaluating and selecting the appropriate machine learning model is crucial for achieving optimal performance. Different metrics are used to assess the model's accuracy, precision, recall, and F1-score, depending on the specific task and the nature of the data. Careful consideration of these metrics helps determine which model best suits the needs of the project.
Choosing the right model involves careful consideration of factors like dataset size, complexity, and the desired level of accuracy. Techniques like cross-validation and hold-out sets are employed to evaluate models on unseen data and prevent overfitting, ensuring the model generalizes well to new, unseen examples.